阿里巴巴Java开发规范
我真的很想一开始就知道各个行业或者某项技能的规范,这样真的能避免走很多弯路。所以,今天来介绍一下Java开发规范,这其中又属阿里巴巴做的非常优秀,真的非常推荐大家,真的是神中神。
编程规约
命名风格
- 类名使用
UpperCamelCase风格,但以下情形例外:DO / BO / DTO / VO / AO / PO等。 - 方法名、参数名、成员变量、局部变量都统一使用
lowerCamelCase风格 - 常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
- 类型与中括号紧挨相连来定义数组,如定义整形数组
int[] arrayDemo;。 - 接口类中的方法和属性不要加任何修饰符号(public 也不要加)
- 枚举类名建议带上Enum后缀,枚举成员名称需要全大写,单词间用下划线隔开。
- service和DAO层命名规约
- 获取单个对象的方法用
get作前缀。 - 获取多个对象的方法用
list作前缀。 - 获取统计值的方法用
count作前缀。 - 插入的方法用
save/insert作前缀。 - 删除的方法用
remove/delete作前缀。 - 修改的方法用
update作前缀。
- 获取单个对象的方法用
- 领域模型命名规约
- 数据对象:
xxxDO,xxx即为数据表名。 - 数据传输对象:
xxxDTO,xxx为业务领域相关的名称。 - 展示对象:
xxxVO,xxx一般为网页名称。 - POJO是DO/DTO/BO/VO的统称,禁止命名成xxxPOJO。
- 数据对象:
- 不要使用一个常量类维护所有常量,按常量功能进行归类,分开维护。
代码格式
- 取消勾选IDEA中
Use tab character,并将tab设置为4个空格。 - 任何二目、三目运算符左右都要加一个空格。
具体可以看这个例子
public static void main(String[] args) { // 缩进4个空格,而不是tab String say = "hello"; // 运算符的左右必须有一个空格 int flag = 0; // 关键词if与括号之间必须有一个空格,括号内的f与左括号,0与右括号不需要空格 if (flag == 0) { System.out.println(say); } // 左大括号前加空格且不换行;左大括号后换行 if (flag == 1) { System.out.println("world"); // 右大括号前换行,右大括号后有else,不用换行 } else { System.out.println("ok"); // 在右大括号后直接结束,则必须换行 }}OOP规约
-
对于类中的静态变量或静态方法,都建议使用类名调用,而不是实例对象调用。
class MyClass {static int staticVariable = 10;static void staticMethod() {System.out.println("This is a static method.");}public static void main(String[] args) {// 正确的访问方式System.out.println(MyClass.staticVariable);MyClass.staticMethod();// 错误的访问方式MyClass myObj = new MyClass();System.out.println(myObj.staticVariable);myObj.staticMethod();}} -
尽量少使用可变参数和Object。如果一定要使用,则将可变参数放在参数列表最后。
// 正确的写法public void method(String arg1, int arg2, Integer... args) {// do something} -
Object的equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals。如
"test".equals(object);或java.util.Objects.equals(object1, object2)。 -
所有POJO类属性必须使用包装数据类型,所有局部变量建议使用基本数据类型。因为可以在初始化的时候可以提醒用户显示赋值。
-
RPC方法的返回值和参数必须使用包装数据类型。RPC(Remote Procedure Call,远程过程调用),就相当于在打电话时,无法直接用对方电话里的东西,而是需要对方把想要传递给你,或者你想要传递给对方的东西,用一个 “包装盒” 装起来,通过网络传输给你。
-
构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在init方法中。
-
循环体内字符串连接用StringBuilder的
append方法,而不应该用“+”号。 -
final关键字的使用- 不允许被继承的类,如:String类。
- 不允许修改引用的域对象,如:POJO类的域变量。
- 不允许被重写的方法,如:POJO类的setter方法。
- 不允许运行过程中重新赋值的局部变量。
- 避免上下文重复使用一个变量,使用final描述可以强制重新定义一个变量,方便更好地进行重构。
-
访问控制关键词
- 如果不允许外部直接通过new来创建对象,那么构造方法必须是private。
- 工具类不允许有public或default构造方法。工具类通常是一些提供静态方法的类,不需要被实例化。我们可以将构造方法设为 private 或没有 public 或 default 构造方法,可以确保外部类无法创建该工具类的对象。
- 类非static成员变量并且与子类共享,必须是protected。
- 类非static成员变量并且仅在本类使用,必须是private。
- 类static成员变量如果仅在本类使用,必须是private。
- 若是static成员变量,必须考虑是否为final。
- 类成员方法只供类内部调用,必须是private。
- 类成员方法只对继承类公开,那么限制为protected。
AOP规约
-
在处理 POST 请求时,传入参数必须添加
@RequestBody注解。如果有很多参数,可考虑使用多层嵌套的DTO对象,也可以以此应对是否必须的复杂参数。 -
对于 GET 请求,不论传入参数和controller方法参数是否一致,都建议添加
@RequestParam注解。 -
切面类方法的入参和返回值,建议使用包装数据类型,而不是使用基本数据类型。
并发控制
-
线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
-
线程池不允许使用Executors去创建,而是通过
ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。FixedThreadPool和SingleThreadPool: 允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。CachedThreadPool和ScheduledThreadPool: 允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
-
使用
Instant代替Date,LocalDateTime代替Calendar,DateTimeFormatter代替SimpleDateFormat。 -
对多个资源、数据库表、对象同时加锁时,需要保持一致的加锁顺序,否则可能会造成死锁。
-
并发修改同一记录时,避免更新丢失,需要加锁。要么在应用层加锁,要么在缓存加锁,要么在数据库层使用乐观锁,使用version作为更新依据。
-
ThreadLocal无法解决共享对象的更新问题,ThreadLocal对象建议使用static修饰。这个变量是针对一个线程内所有操作共享的,所以设置为静态变量,所有此类实例共享此静态变量 ,也就是说在类第一次被使用时装载,只分配一块存储空间,所有此类的对象(只要是这个线程内定义的)都可以操控这个变量。
控制语句
-
在if/else/for/while/do语句中必须使用大括号。即使只有一行代码,避免采用单行的编码方式。
-
在高并发场景中,避免使用“等于”判断作为中断或退出的条件。不然,比如判断剩余奖品数量等于0时,终止发放奖品,但因为并发处理错误导致奖品数量瞬间变成了负数,这样的话,活动无法终止。
-
除常用方法(如getXxx/isXxx)等外,不要在条件判断中执行其它复杂的语句,将复杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性。
final boolean existed = (file.open(fileName, "w") != null) && (...) || (...);if (existed) {...}
注释规约
- 类、类属性、类方法的注释必须使用Javadoc规范,使用/*内容/格式,不得使用// xxx方式。
- 待办事宜(TODO):( 标记人,标记时间,[预计处理时间])表示需要实现,但目前还未实现的功能。
- 错误,不能工作(FIXME):(标记人,标记时间,[预计处理时间])在注释中用FIXME标记某代码是错误的,而且不能工作,需要及时纠正的情况。
异常日志
异常处理
- 异常不要用来做流程控制,条件控制。
- 不要在
finally块中使用return。finally块中的return返回后方法结束执行,不会再执行try块中的return语句。 - 远程调用返回对象时,一律要求进行空指针判断,防止NPE。使用JDK8的
Optional类来防止NPE(Null Pointer Exception)问题。 - 对于公司外的http/api开放接口必须使用“错误码”;而应用内部推荐异常抛出;跨应用间RPC调用优先考虑使用Result方式,封装isSuccess()方法、“错误码”、“错误简短信息”。
日志规约
-
使用日志框架SLF4J中的API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
import org.slf4j.Logger;import org.slf4j.LoggerFactory;private static final Logger logger = LoggerFactory.getLogger(Abc.class); -
日志文件推荐至少保存15天,因为有些异常具备以“周”为频次发生的特点。
-
对trace/debug/info级别的日志输出,必须使用条件输出形式或者使用占位符的方式。如
logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);。 -
生产环境禁止输出
debug日志;有选择地输出info日志;如果使用warn来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。 -
使用
warn日志级别来记录用户输入参数错误的情况。error级别只记录系统逻辑出错、异常或者重要的错误信息。
其他
- 针对统计时间等场景,推荐使用
Instant类。 - 不要在视图模板中加入任何复杂的逻辑。根据MVC理论,视图的职责是展示,不要抢模型和控制器的活。
- 获取当前毫秒数应该使用
System.currentTimeMillis();。
单元测试
- 输出结果需要人工检查的测试不是一个好的单元测试。单元测试中不准使用
System.out来进行人肉验证,必须使用assert来验证。 - 对于单元测试,要保证测试粒度足够小,有助于精确定位问题。单测粒度至多是类级别,一般是方法级别。
- 单元测试代码必须写在如下工程目录:src/test/java,不允许写在业务代码目录下。
- 对于数据库相关的查询,更新,删除等操作,不能假设数据库里的数据是存在的,或者直接操作数据库把数据插入进去,请使用程序插入或者导入数据的方式来准备数据。
- 和数据库相关的单元测试,可以设定自动回滚机制,不给数据库造成脏数据。或者对单元测试产生的数据有明确的前后缀标识。
- 多层条件语句建议使用卫语句(即先判断执行可能会直接退出的语句,以防止进一步判断导致嵌套)、策略模式、状态模式等方式重构。也就是减少构造函数复杂度,减少全局变量和静态方法,减少外部依赖,减少条件语句。
安全规约
-
隶属于用户个人的页面或者功能必须进行权限控制校验。注册登录等界面要排除在外。
-
用户敏感数据禁止直接展示,必须对展示数据进行脱敏。如个人手机号码显示为
158****9119,隐藏中间4位。 -
用户请求传入的任何参数必须做有效性验证。如手机号格式验证等。
-
不允许在数据库中明文存储密码,必须使用安全的加密算法对密码进行加密。如采用盐值加密,盐可以存放在配置文件、数据库、项目文件等。
-
在使用平台资源,譬如短信、邮件、电话、下单、支付,必须实现正确的防重放限制。比如登录时的验证码,在60秒内禁止重复发送。如果注册时发送验证码到手机,如果没有限制次数和频率,那么可以利用此功能骚扰到其它用户,并造成短信平台资源浪费。
-
发贴、评论、发送即时消息等用户生成内容的场景必须实现防刷、文本内容违禁词过滤等风控策略。
数据库
建表规约
-
表必备三字段:
id,gmt_create,gmt_modified。其中id必为主键,类型为unsigned bigint、单表时自增、步长为1。gmt_create,gmt_modified的类型均为datetime类型,前者现在时表示主动创建,后者过去分词表示被动更新。 -
表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。MySQL在Windows下不区分大小写,但在Linux下默认是区分大小写,所以统一只用小写。
-
主键索引名为
prime_key字段名;唯一索引名为unique key字段名;普通索引名则为idx字段名。 -
小数类型为
decimal,禁止使用float和double。float和double在存储的时候,存在精度损失的问题。如果存储的数据范围超过decimal的范围,建议将数据拆成整数和小数分开存储。 -
如果存储的字符串长度几乎相等,使用
char定长字符串类型。 -
varchar是可变长字符串,不预先分配存储空间,长度不要超过5000,如果存储长度大于此值,定义字段类型为text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。 -
表达是与否概念的字段,必须使用
is_xxx的方式命名,数据类型是unsigned tinyint( 1表示是,0表示否)。比如表达逻辑删除的字段名is_deleted,1表示删除,0表示未删除。 -
单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
索引规约
-
超过三个表禁止
join。需要join的字段,数据类型必须绝对一致;多表关联查询时,保证被关联的字段需要有索引。 -
业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
-
利用覆盖索引来进行查询操作,避免回表。如果一本书需要知道第11章是什么标题,浏览目录即可,不需要翻开第11章对应的那一页。
SQL语句
-
不要使用
count(列名)或count(常量)来替代count()。因为count(*)会统计值为NULL的行,而count(列名)不会统计此列为NULL值的行。 -
count(distinct col)计算该列除NULL之外的不重复行数,注意count(distinct col1, col2)如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。 -
当某一列的值全是NULL时,
count(col)的返回结果为0,但sum(col)的返回结果为NULL,因此使用sum()时需注意NPE问题。可以采用如下方式避免NPESELECT IF(ISNULL(SUM(g)),0,SUM(g)) FROM table;。 -
使用ISNULL()来判断是否为NULL值。 说明:NULL与任何值的直接比较都为NULL。
-
在代码中写分页查询逻辑时,若count为0应直接返回,避免执行后面的分页语句。
-
不得使用外键与级联,一切外键概念必须在应用层解决。以学生和成绩的关系为例,学生表中的
student_id是主键,那么成绩表中的student_id则为外键。如果更新学生表中的student_id,同时触发成绩表中的student_id更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。 -
数据订正(特别是删除、修改记录操作)时,要先
select,避免出现误删除,确认无误才能执行更新语句。 -
in操作能避免则避免,若实在避免不了,需要仔细评估in后边的集合元素数量,控制在1000个之内。
ORM映射
-
在表查询中,一律不要使用
*作为查询的字段列表,需要哪些字段必须明确写明。 -
POJO类的布尔属性不能加
is,而数据库字段必须加is_,要求在resultMap中进行字段与属性之间的映射。我们在使用 Mybatis Generator 生成后需要手动修改,同时增加映射是必须的。 -
不要用
resultClass当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义;反过来,每一个表也必然有一个与之对应。也就是说,不管怎样都不要直接返回插件自动生成的、由数据库生成的pojo类,而是需要用一个VO类来返回。 -
不允许直接拿
HashMap与Hashtable作为查询结果集的输出。 -
更新数据表记录时,必须同时更新记录对应的
gmt_modified字段值为当前时间。因为我们之前提到过表中必有ID、gmt_create、gmt_modified三个字段。 -
不要写一个大而全的数据更新接口。更新哪些就专注于更新哪些,不要为了更新某个字段,而更新了所有字段。
工程结构
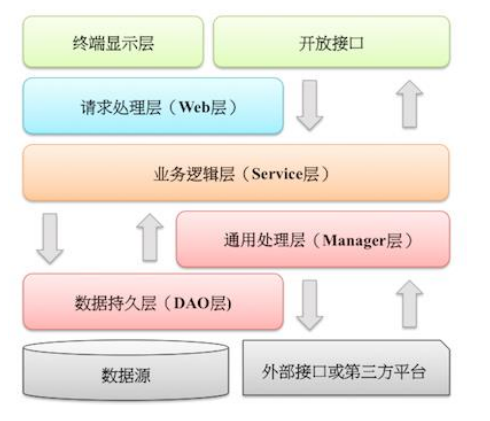
应用分层
开放接口层:可以理解为contoller的接口,在Web交互中封装成HTTP接口,在分布式系统中暴露Service方法为RPC接口。同时也可以进行网络安全控制和流量控制。
终端控制层:各个端的模板渲染并执行显示的层。
Web层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
Service层:相对具体的业务逻辑服务层。包括ServiceImpl来具体实现那些抽象接口。
Manager层:通用的业务处理层。有对第三方平台的封装;对Service层通用能力的下沉,比如各种中间件等;与DAO层交互,封装SQL、DTO等对象,或是组合复用。
DAO层:数据访问层,与底层数据库交互,实现数据库的CRUD操作。
-
DAO层产生的异常应该采用
catch(Exception e)的方式进行处理,并throw new DAOException(e)抛出DAO层自己的异常,而不是打印日志。 -
Manager/Service层的异常需要被捕获并打印打日志文件中,进行持久化的记录。
-
Web层绝不应该继续往上抛异常,因为已经处于顶层,如果意识到这个异常将导致页面无法正常渲染,那么就应该跳转到友好错误页面,加上用户容易理解的错误提示信息。
-
开放接口层要将异常处理成错误码和错误信息方式返回。
-
分层领域模型规约:
- DO(Data Object):与数据库表结构一一对应,通过DAO层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service或Manager向外传输的对象。
- BO(Business Object):业务对象。由Service层输出的封装业务逻辑的对象。
- AO(Application Object):应用对象。在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
- VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象。
- Query:数据查询对象,各层接收上层的查询请求。注意超过2个参数的查询封装,禁止使用Map类来传输。
二方库依赖
一方库: 本工程内部子项目模块依赖的库(jar包)。
二方库: 公司内部发布到中央仓库,可供公司内部其它应用依赖的库(jar包)。
三方库: 公司之外的开源库(jar包)。
-
二方库版本号命名方式:
主版本号.次版本号.修订号。注意起始版本号必须为:1.0.0,而不是0.0.1。如当前版本:1.3.3,那么下一个合理的版本号:1.3.4 或 1.4.0 或 2.0.0。- 主版本号:产品方向改变,或者大规模API不兼容,或者架构不兼容升级。
- 次版本号:保持相对兼容性,增加主要功能特性,影响范围极小的API不兼容修改。
- 修订号:保持完全兼容性,修复BUG、新增次要功能特性等。
-
所有pom文件中的依赖声明放在
<dependencies>语句块中,所有版本仲裁放在<dependencyManagement>语句块中(也就是声明依赖版本号)。子项目需要显式声明依赖,但version和scope都读自父pom,子项目的<dependencies>会默认继承在主pom的<dependencies>里的依赖。 -
二方库的新增或升级,保持除功能点之外的其它jar包仲裁结果不变。如果有改变,必须明确评估和验证,建议进行
dependency:resolve前后信息比对,如果仲裁结果完全不一致,那么通过dependency:tree命令,找出差异点,进行<excludes>排除jar包。 -
依赖于一个二方库群时,必须定义一个统一的版本变量,避免版本号不一致。比如我们导入spring相关的若干框架,采用一个变量保存比如
${spring.version}。 -
二方库里可以定义枚举(enum)类型,参数可以使用枚举类型,但是接口返回值不允许使用枚举类型或者包含枚举类型的POJO对象。
-
禁止在子项目的pom依赖中出现相同的GroupId,相同的ArtifactId,但是不同的Version。
-
线上应用不要依赖
SNAPSHOT版本(安全包除外)。SNAPSHOT指那些不稳定、尚处于开发中的版本,也叫快照版本,与RELEASE版本相对。如果无法避免依赖,说明命名就有问题。 -
二方库不要有配置项,最低限度不要再增加配置项。也可以使用nacos进行配置管理,取出独立模块的配置。
服务器
-
高并发服务器建议调小TCP协议的
time_wait超时时间。比如,在linux服务器上请通过变更/etc/sysctl.conf文件去修改该缺省值(秒):net.ipv4.tcp_fin_timeout = 30 -
调大服务器所支持的最大文件句柄数(fd),最大句柄数跟内存挂钩,一般跳到比默认大几倍。
-
服务器内部重定向使用forward;外部重定向地址使用URL拼装工具类来生成。
-
在线上生产环境,JVM的Xms和Xmx设置一样大小的内存容量,避免在 GC 后调整堆大小带来的压力。